- Background
- Updates to the Privacy Notice
- Firefox 56: Mozilla Enables Telemetry by Default for the First Time
- Feedback
Background
Mozilla introduced a “Terms of Use” for Firefox for the first time two weeks ago, and since then, I have been trying to figure out what has changed and where to go from here.
Once Mozilla updated their ToU and the initial outcry over the possibility of Mozilla owning information transmitted via Firefox died down, I was surprised to learn that Mozilla recommended that people can opt out of having their data processed for advertising purposes by turning off a setting related to “technical and interaction data”.
I read with surprise:
Mozilla also clarified how it works with advertisers, explaining that it does sell advertising in Firefox as part of how it funds development of the browser.
“It’s part of Mozilla’s focus to build privacy-preserving ads products that improve best practices across the industry,” the spokesperson said. “In cases where we serve ads on Firefox surfaces (such as the New Tab page) we only collect and share data as set out in the Privacy Notice, which states that we only share data with our advertising partners on a de-identified or aggregated basis.”
The company said that users can opt out of having their data processed for advertising purposes by turning off a setting related to “technical and interaction data” on both desktop and mobile at any time.
Ever since this setting has existed, Mozilla contributors and employees have told people to enable it, in order to ensure that Mozilla developers have insight into how people use Firefox, to help make Firefox better. While this post will prove my (naive) impression wrong, I had never seen anyone mention that this setting shared data with advertisers.
And yet, that is what Mozilla is telling us.
The Preference
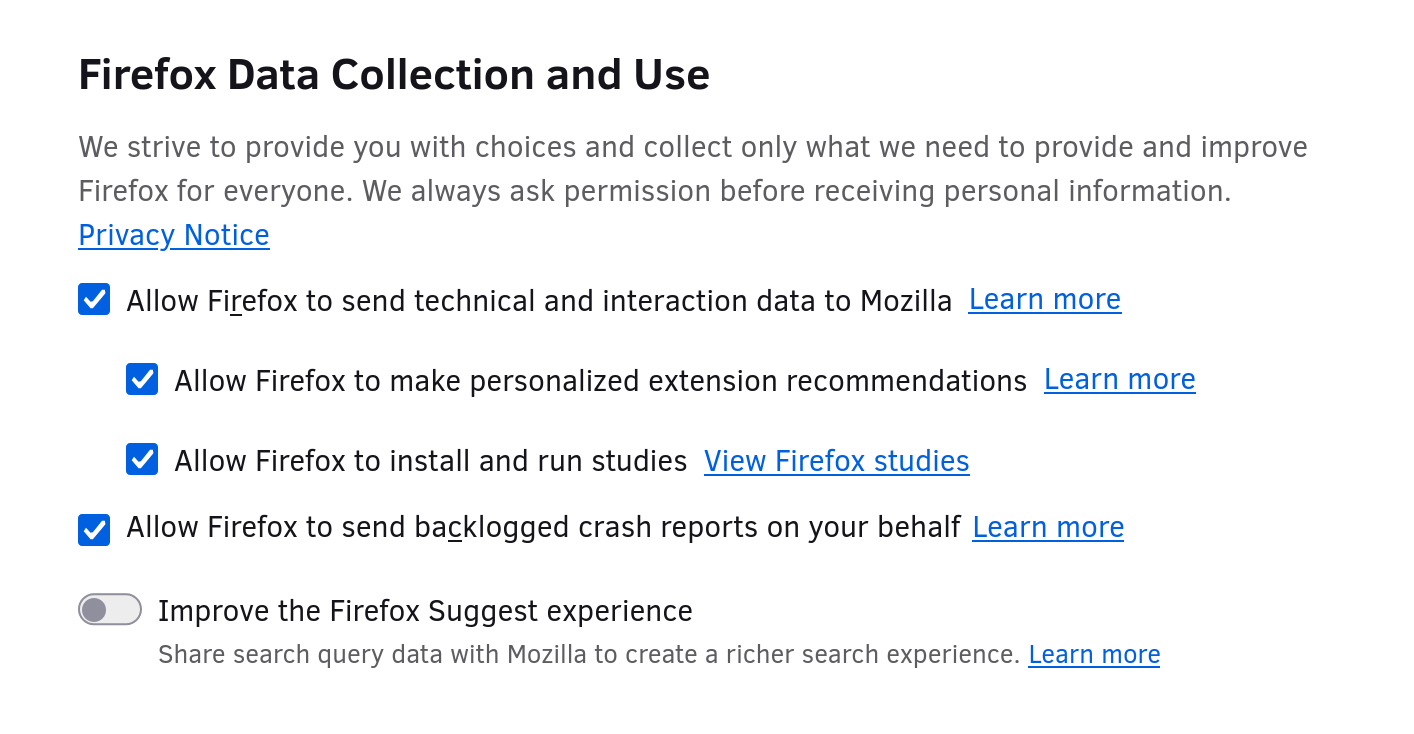
Take a look at the Firefox Preferences UI that Mozilla is telling us to toggle if we don’t want our data being processed for ads. I don’t see anything here says that this setting is about sharing data with advertisers. I have to go to the Privacy Notice to understand that. That doesn’t feel very upfront to me.
Updates to the Privacy Notice
Once the updated Privacy Notice was posted, I looked closer at the new notice and surprised myself.
Since Mozilla was saying that the changes in language had been to clarify “broad and evolving” definitions of the legal definition of the “sale of data” not because of any change in the way data was processed or in how the product worked, I got even more confused. How could I have gotten it so wrong?
The New Privacy Notice
The new privacy notice is pretty easy to read, and the places where settings for technical and interaction data are implicated are pretty easy to find - including for sponsored content and ads - both Firefox New Tab and Review Checker are called out specifically as showing “advertising” and “sponsored content”.
In the new notice, Mozilla says:
To serve relevant content and advertising on Firefox New Tab
We use technical data, language preference, and location to serve content and advertising on the Firefox New Tab page in the correct format (i.e. for mobile vs desktop), language, and relevant location. Mozilla collects technical and interaction data, such as the position, size, views and clicks on New Tab content or ads, to understand how people are interacting with our content and to personalize future content, including sponsored content. This data may be shared with our advertising partners on a de-identified or aggregated basis.
In some instances, when ads are enabled on New Tab, additional browsing data may also be processed locally on your device to measure the effectiveness of those ads; such data will only be shared with Mozilla and/or our advertising partners via our privacy-preserving technologies on an aggregated and/or de-identified basis.
When a user visits a third-party website by clicking an advertisement or link in Firefox, that site may use cookies and other web APIs available to any website to collect data subject to that website’s privacy and/or cookie notices.
More details, including how to adjust your data settings: You can read more information about how to manage your New Tab page including your data settings. You can opt out of having your data processed for personalization or advertising purposes by turning off “technical and interaction data” on Desktop and Mobile at any time.
Mozilla is pretty clear here in saying that “Mozilla collects technical and interaction data … to understand how people are interacting with our content and to personalize future content, including sponsored content. This data may be shared with our advertising partners on a de-identified or aggregated basis.”.
Remember that Mozilla is telling us that nothing is changing - this Privacy Notice and associated product changes are intended to clarify the existing way that Firefox works. That means that we can look at the previous privacy notices to see how I missed something so obvious.
Firefox 56: Mozilla Enables Telemetry by Default for the First Time
On September 28 2017, Mozilla released Firefox 56 and updated its privacy notice.
The relevant sections from this Privacy Notice are:
Firefox by default shares data to: Improve performance and stability for users everywhere
Interaction data: Firefox sends data about your interactions with Firefox to us (such as number of open tabs and windows; number of webpages visited; number and type of installed Firefox Add-ons; and session length) and Firefox features offered by Mozilla or our partners (such as interaction with Firefox search features and search partner referrals).
Technical data: Firefox sends data about your Firefox version and language; device operating system and hardware configuration; memory, basic information about crashes and errors; outcome of automated processes like updates, safebrowsing, and activation to us. When Firefox sends data to us, your IP address is temporarily collected as part of our server logs.
Read the telemetry documentation for Desktop, Android, or iOS or learn how to opt-out of this data collection.
…
Suggest relevant content
Firefox displays content, such as “Snippets” (messages from Mozilla) and Top Sites (websites suggested by Mozilla for first-time Firefox users).
Location data: Firefox uses your IP address to suggest relevant content based on your country.
Technical & Interaction data: Firefox sends us data such as the position, size and placement of content we suggest, as well as basic data about your interactions with Firefox’s suggested content. This includes the number of times suggested content is displayed or clicked.
It’s right there - Mozilla is getting the “position, size and placement of content we suggest, as well as basic data about your interactions with Firefox’s suggested content” (when Mozilla says suggested content here, it seems to be obfuscating that they are talking about ads).
So I definitely missed it, but also - there was no way that it was always the case that technical and interaction data was always used for ads – after all, the New Tab page hadn’t existed the entire time that “technical and interaction data” existed… right?
About that.
It seems that Firefox 56 came with product UI changes that updated some old checkboxes.
In Firefox 55, “Telemetry” was a checkbox that was not checked by default, and it appeared alongside the “Firefox Health Report”:
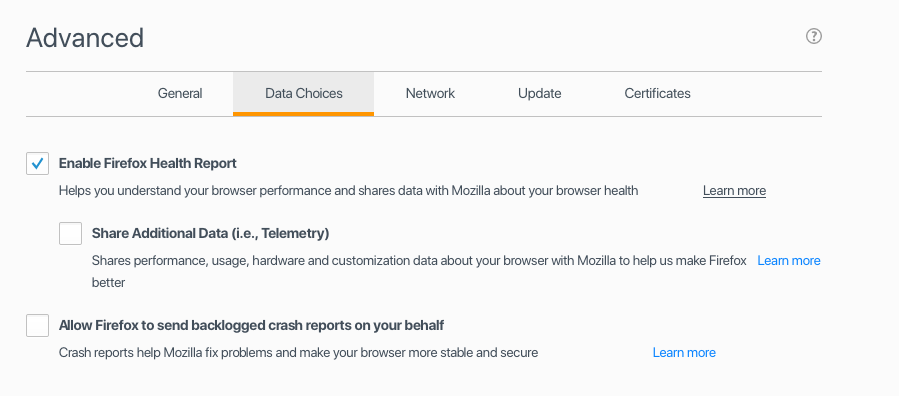
In Firefox 56, Mozilla combined the old Firefox Health Report and Telemetry checkboxes into a single checkbox for “technical and interaction data”.

It’s finally making sense. Mozilla reduced granularity into the options for data collection in Firefox, enabled additional data collection by default, and gave itself the ability to use this new data for advertising purposes. Users would have to opt out of this data collection for it not to be used for advertising purposes (a purpose that Mozilla in this iteration is not forthright about).
The previous Privacy Notice included this section:
Usage statistics (also called “Telemetry” in non-release builds)
Usage statistics or “Telemetry” is a feature in Firefox that sends Mozilla usage, performance, and responsiveness statistics about user interface features, memory, and hardware configuration. Your IP address is also collected as a part of a standard web log. Usage statistics are transmitted using SSL and help us improve future versions of Firefox. Once sent to Mozilla, usage statistics are aggregated and made available to a broad range of developers, including both Mozilla employees and public contributors. When Telemetry is enabled, certain short-term experiments may collect information about visited sites.
This feature is turned on by default in Nightly, Developer Edition (Aurora), and Beta builds of Firefox to help those users provide feedback to Mozilla. In the general release version of Firefox, this feature is turned off by default.
You can learn more about Telemetry here and how to enable or disable it.
jwz likes to say that Mozilla bundling DRM in Firefox is its original sin, but if it isn’t that, allowing opt-out data collection has to be a candidate. Unfortunately, it seems that once a company has data (including your data), they tend to see it as an asset to be monetized – and while Mozilla has shown great restraint, they are continuing down a troubling path.
I looked on reddit and the general tech press to see if the community had understood what is obvious today – enabling this setting by default allowed Mozilla to further monetize the new tab page. I found afnan-khan’s sad submission of Mozilla’s privacy notice post. 13 net upvotes, 0 comments.
A massively consequential change with regards to data sharing in advertising, and the community had nothing to say about it.
At this point, I’ve satisfied myself on how I fooled myself – I had been running Firefox for years, I had telemetry enabled, and telemetry had never been used for ads. Once Mozilla created an umbrella for “technical and interaction data”, I continued to see it as “telemetry” and believed it to continue to be innocuous.
Instead, Mozilla had successfully enabled data collection in its largest user population (the release branch of Firefox) and was now able to use that data for advertising purposes. That wasn’t how it was reported, that isn’t how we saw it - but that seems to be what happened.
People who had willingly opted into sharing telemetry data by running Nightly or Beta builds to help Mozilla make a better product – those are the people who are blindsided by this change. We chose to opt in to share data with Mozilla, and the way that the data was used changed after we made our decision – and it wasn’t really clear that it was the case.
It reminds me of how I felt once reddit started selling content freely given by users to AI companies - they were within their rights, but my expectations had been breached.
I thought by now that I would have a path forward on how I wanted to move forward in my browser usage. It hasn’t worked out that way. I wish we had more clarity from Mozilla on how data is used - I still want to help build Firefox. I hate that Mozilla has made this decision so hard - why must I get into bed with ad-tech in order to help Mozilla build a better product? Is that really the bargain we have struck?
Feedback
How is Mozilla going to get paid for the ads on the new tab page?
I got some feedback:
If you read about the details, this is about anonymized information about the ads in the newtab page. How do you figure Mozilla is getting paid for those without any information about their effect.
I’m going to respond to that question with a related question – how does Mozilla get paid for the ads that appear when “technical and interaction data” sharing is disabled? If you think Mozilla isn’t getting paid for those ads, do you think Mozilla is displaying those ads without any expectation of getting paid?
Given that Firefox is presumably getting paid for ads that people interact with even if they aren’t sharing technical and interaction data, why does Mozilla need the additional information?
If you liked this material, please consider supporting me. You can message me or follow this blog on Mastodon.
]]>